ทั้ง TSO และ ISPF เป็น application software เหมือนกับ software ทั่วๆ ไปบน windows แต่สองตัวนี้จะใช้เป็น software หลักๆ บน Mainframe
TSO (Time Sharing Option)
TSO เป็น software ที่เทียบได้กับ command.exe บน windows ที่คอยรับคำสั่งจาก user ไปทำงาน โดยใช้หลักการ time sharing คือ คอมพิวเตอร์ที่ต่อกับ terminal หลายตัว จะแบ่งทำงานตามคำสั่งที่ได้รับ โดย ณ.เวลาหนึ่งจะทำงานแค่คำสั่งเดียวเท่านั้น แต่การทำงานจะเป็นไปอย่างรวดเร็ว ทำให้ดูเสมือนว่าทำงานสนับสนุน terminal หลายตัวไปพร้อมกัน

หลังจากนั้นก็ log in โดยใส่ user id

จากหน้าจอ log in เมื่อจะเข้าใช้ TSO (Time Sharing Option) จะเห็นหน้าจอ Log On Parameter คล้ายๆ กันดังนี้

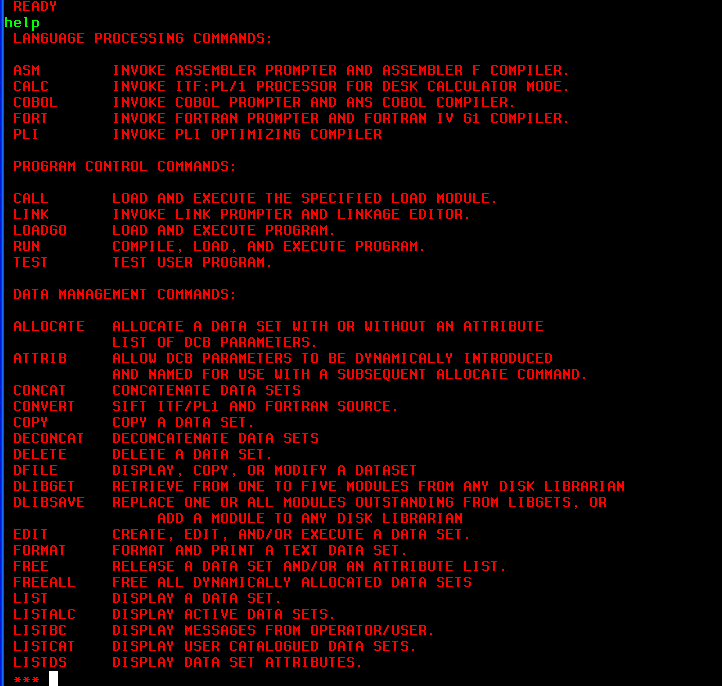
เมื่อเข้ามาแล้ว ก็เป็นอันเสร็จ เราสามารถ run command ต่างๆ ต่อไป หรือถ้าต้องการดู help ให้พิมพ์ help ก็จะได้หน้าจอประมาณนี้ (ทั้งนี้แตกต่างกันไปแล้วแต่ config ของเครื่องนั้นๆ )
ISPF (Interactive System Productivity Facility)
เนื่องจากความยากในการใช้งานของ TSO ซึ่งจะต้องจำ coommand และลำดับของ parameter ต่างๆ ISPF จึงเกิดขึ้นเพื่อช่วยให้สามารถใช้คำสั่งต่างๆ ได้อย่างสะดวกขึ้น
สำหรับ ISPF ซึ่งจะต้องเรียกผ่าน TSO อีกที โดยพิมพ์ command ISPF ที่หน้าจอ TSO หลังจากที่ มันแสดง TSO ready prompt

เมื่อเข้าหน้าจอ ISPF แล้ว จะแสดงหน้าจอประมาณนี้

ซึ่งเมนูมีอะไรบ้างนั้น ก็จะขึ้นอยู่กับแต่ละเครื่องจะ config อีกเ่ช่นเดียวกัน ISPF จะเปรียบเหมือนหน้า desktop บน windows แต่ละเมนู คือ application ซึ่งแต่ละเครื่องก็จะมี application ให้ใช้แตกต่างกันไป
การจะใช้ ISPF จะใช้ร่วมกับ program function keys (PF keys) หรือ ไอ้ปุ่ม F1 - F12 บนแป้น keyboard เรานั่นแหละ ซึ่ง user แต่ละคนสามารถกำหนดหน้าที่ของแต่ละ function key ได้เอง แต่โดยมาตรฐานแล้วจะกำหนดไว้คล้ายๆ กัน ดังนี้
PF13 <-- Shift + PF1 PF14 <-- Shift + PF2 ... เราสามารถให้มันแสดง function key ไว้ข้างใต้หน้าจอ โดยพิมพ์ PFSHOW ON หรือถ้าจะไม่ให้แสดงก็พิมพ์ PFSHOW OFF ได้เช่นกัน
Reference:
Using TSO and ISPF
เมื่อเข้าหน้าจอ ISPF แล้ว จะแสดงหน้าจอประมาณนี้

ซึ่งเมนูมีอะไรบ้างนั้น ก็จะขึ้นอยู่กับแต่ละเครื่องจะ config อีกเ่ช่นเดียวกัน ISPF จะเปรียบเหมือนหน้า desktop บน windows แต่ละเมนู คือ application ซึ่งแต่ละเครื่องก็จะมี application ให้ใช้แตกต่างกันไป
การจะใช้ ISPF จะใช้ร่วมกับ program function keys (PF keys) หรือ ไอ้ปุ่ม F1 - F12 บนแป้น keyboard เรานั่นแหละ ซึ่ง user แต่ละคนสามารถกำหนดหน้าที่ของแต่ละ function key ได้เอง แต่โดยมาตรฐานแล้วจะกำหนดไว้คล้ายๆ กัน ดังนี้
- PF1 = Help
- PF2 = Split: Split the session (lets you use two functions of TSO at the same time.)
- PF3 = End
- PF4 = Return
- PF5 = Rfind (repeat last find)
- PF6 = Rchange (repeat last change)
- PF7 = Move Backward
- PF8 = Move forweard
- PF9 = Switch between screeens during a split session; goes with PF 2
- PF10 = Move left
- PF11 = Move right
- PF12 = Retrieve last command
PF13 <-- Shift + PF1 PF14 <-- Shift + PF2 ... เราสามารถให้มันแสดง function key ไว้ข้างใต้หน้าจอ โดยพิมพ์ PFSHOW ON หรือถ้าจะไม่ให้แสดงก็พิมพ์ PFSHOW OFF ได้เช่นกัน
Reference:
Using TSO and ISPF













